MongoDB Tutorial 4 - Performance
Table of Contents
![]()
Storage engine
Storage engine sits between mongodb server and the file storage. Use db.serverStatus().storageEngine; to check.
WiredTiger
for many applications, this is faster - document level concurrency, lock free implementation. optimistic concurrency model which assumes two writes not gonna be on same document. if on same, one write unwound and try again. - compression of data and indexes. WiredTiger manages memory. - append only, no in place updates
MMAP V1
Uses mmap system call undercovers. Allocating memory, or map files or devices into memory. Operation system manages memory/virtual memory.
- collection level locking, multiple reader, single writer lock.
- in place update (database does not have to allocate and write a full new copy of the object).
- power of 2 sizes when allocating initial storage with a minimum of 32 bytes.
Indexes
Built with btree or b+trees. With indexes writes are slower, reads are much faster. Without index, query on 10 million documents will be linear searching, too much disk io.
(a,b,c) leftmost index order. a, (a,b), (a,b,c) would work, (a,c) partially work, others do not.
Indexes Size
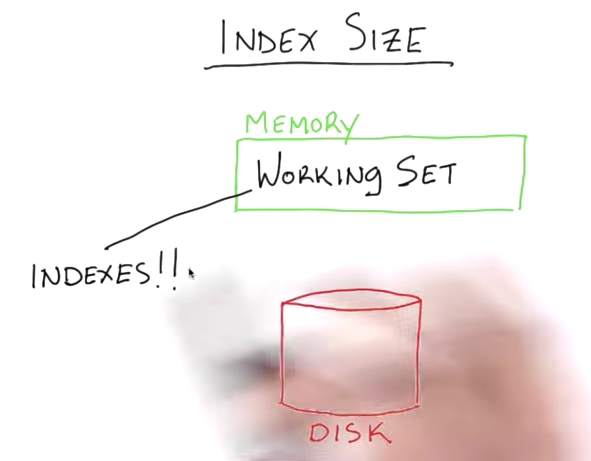
It’s essential to fit working set (key component: Indexes) into memory. To check indexes sizes in mongo shell:
db.collection.stats() //detailed for each index
db.collection.totalIndexSize() //just the total
For a 10 million documents students collection, each index is about 300 Mb with MMAP V1 storage engine. Since 3.0, the wired tiger storage engine provides a few types of compression, one of which, i.e., prefix compression allows us to have smaller indexes. The same index is about 100 Mb instead of 300 Mb. The compression comes at the cost of CPU and whether the dataset can take advantage of something like prefix compression.
Number of Index Entries (Cardinality)
- Regular: 1:1 proportional to collection size (index point needed even for null)
- Sparse: <= number of documents
- Multikey: index point for every array element. Could be (significantly) greater than number of documents.
If a document is updated and needs to be moved, the indexes need to be moved too. That cost only exists in the MMAPv1 storage engine. In the WiredTiger storage engine, index entries don’t contain pointers to actual disk locations. Instead, in WiredTiger, the index points to an internal document identifier (the Record Id that is immutable. Therefore, when a document is updated, its index does not need to be updated at all.
Geospatial Indexes
2D Type
Allows to find things based on location. Documents have 'location':[x,y] stored in them representing establishments around a person such as restaurants or coffee shops. createIndex({'location':'2d', type:1}) (2d is reserved type for two dimensional geo indexes). Use
find({location:{$near:[x0,y0]}}).limit(20)
to find closest establishments where $near is a query operator and [x0,y0] is ther person’s standing point.
Sperical Type
MongoDB supports a subset of
GeoJSON location specification
. A GeoJSON document is used for the value of key location. Google maps shows @latitude,longitude as part of the url for a particular location. MongoDB takes an opposite order @longitude,latitude. Although it’s a spherical model, it’s only looking at points at the surface of the sphere other than points in the air.
First, create indexes,
db.places.createIndex({'location':'2dsphere'})
then, to find nearest point to hoover tower, in geonear.js,
db.places.find(
location:{
$near:{
$geometry:{
type:"Point",
coordinates:[-122,37]// hoover tower
},
$maxDistance:2000 // in meters
}
}).pretty()
to run the above query,
mongo < geonear.js
Text Indexes
aka Full text search index. Typically, when searching strings, the entire string must match. Except that a regex search will search the index (rather than the full collection), and if you anchor it on the left by beginning with ^, you can often do better still. Here’s a link to the documentation . Alternatively, put every word into an array and use set operators.
db.sentences.createIndex({'words':'text'})
db.sentences.find({$text:{$search:'dog'}})
A regular search db.sentences.find({'words':'dog'}) will return nothing.
We can rank the results by a score,
db.sentences.find(
{$text:{$search:'dog tree obsidian'}},
{$score:{$meta:'textScore'}}
).sort({$score:{$meta:'textScore'}})
Index Design
The goal is efficient read/write operations.
- Selectivity - minimize number of records scanned for a given query pattern.
- Other Ops - how sorts are handled?
Example query for 1 million student records:
db.students.find(
{student_id:{$gt:500000}, class_id:54})
.sort({student_id:1}).hint({class_id:1} // specify index shape
).explain("executionstats")
Note without hint(), "totalKeysExamined" : 850433 >> "nReturned" : 10118, so index was not very selective. Check queryPlanner, winningPlan, and rejectedPlans section, the student id query examines half of the collection. A query using class_id as an index would need a in memory sort ("stage" : "SORT") instead of one within the database so was rejected. With hint() "totalKeysExamined" : 20071. "executionTimeMillis" also dropped to 79 ms from 2600 ms.
With db.students.createIndex({class_id:1, student_id:1}) we will be using the most selective part of the query which is an equality/point query other than the range query on the student_id. Generally speaking, order equality queries first when building a compound index.
With the above compound index and query below,
db.students.find(
{student_id:{$gt:500000}, class_id:54}).sort({final_grade:1})
).explain("executionstats")
"totalKeysExamined" and nReturned are 10118, executionTimeMillis 138 ms with in memory sort on final_grade done. It’s good to avoid in memory sort when you can, the trade off is to examine a few more keys. We can create another compound index, db.students.createIndex({class_id:1, final_grade:1, student_id:1}), final_grade has to be immediately after class_id since we want to walk the index keys in order.
db.students.find(
{student_id:{$gt:500000}, class_id:54}).sort({final_grade:-1})
).explain("executionstats")
Now the result show executionTimeMillis : 27 and "totalKeysExamined": 10204. The winningPlan now does not have a sort stage, only a FETCH stage.
MongoDB can walk the index backward in order to sort on the final_grade field. While true given that we are sorting on only this field, if we want to sort on multiple fields, the direction of each field on which we want to sort in a query must be the same as the direction of each field specified in the index. So if we want to sort using something like db.collection.find( { a: 75 } ).sort( { a: 1, b: -1 } ), we must specify the index using the same directions, e.g., db.collection.createIndex( { a: 1, b: -1 } ).
In general, the rules of thumb is * Equality fields before range fields * Sort fields before range fields * Equality fields before sort fields
Logging Slow queries
Slow queries longer than 100 ms are already automatically logged with the default logging facility. It takes about 4 s for db.students.find({student_id:10000}) without an index among 1 million student documents.
There is a profiler built in mongod, which is a more sophisticated facility and writes documents entries to system.profile any query taking more than specified time.
- level 0 off
- level 1 log slow queries
- level 2 log all queries, general debugging
To start the profiler,
mongod -dbpath /usr/local/var/mongodb --profile 1 --slowm 2
# logs queries above 2 ms
Use db.system.profile.find().pretty() to check for slow queries. For the same above query,
"query":{
"student_id" : 10000
}
"ntoreturn" : 0,
"nscanned" : 10000000,
...
"nReturned" : 1
"millis" : 4231
This is a cap (fixed size) collection, recycle after it get used up. Some example usages below,
> db.system.profile.find({ns:/school.students/}).sort(ts:1).pretty()
// namespace school database, students collection, sort by timestamp.
> db.system.profile.find({millis:{$gt:1}}).sort(ts:1).pretty()
// looks for queries longer than 1 ms.
> db.getProfilingLevel()
1
> db.getProfilingStatus()
{"was" : 1, "slowms" : 2}
> db.setProfilingLevel(1, 4) // slow queries above 4 ms
{"was" : 1, "slowms" : 2, "ok" : 1}
> db.setProfilingLevel(0)
{"was" : 1, "slowms" : 4, "ok" : 1}
mongotop and mongostat
mongotop is named after unix top, which gives a high level view where mongo spends most of its time. Subsequently, one can follow up for more detailed examining and optimizing.
$ mongotop 3 # default returns every second, this set to 3 seconds
ns total read write 2016-06-25T23:32:52-07:00
admin.system.roles 0ms 0ms 0ms
admin.system.version 0ms 0ms 0ms
blog.posts 0ms 0ms 0ms
blog.sessions 0ms 0ms 0ms
mongostat is a performance tuning command, similar to unix iostat samples the database at 1 second increments and give information such as number of queries, inserts, updates, deletes, .etc. getmore is getting more from a cursor for a query with a large result. qr|qw ar|aw are queues and active reads and writes. %dirty %used refers to percentage of WiredTiger cache. res resident memory size smaller for WiredTiger. For MMAPv1 engine, faults number of page faults and for WiredTiger, %used cache can indicate amount of IO being used. Check fields section for
mongostat doc
.
$ mongostat [--port 27017]
insert query update delete getmore command % dirty % used res qr|qw ar|aw netIn netOut
*0 *0 *0 *0 0 1|0 0.0 0.0 52.0M 0|0 0|0 79b 18k
*0 *0 *0 *0 0 1|0 0.0 0.0 52.0M 0|0 0|0 79b 18k
Sharding Overview
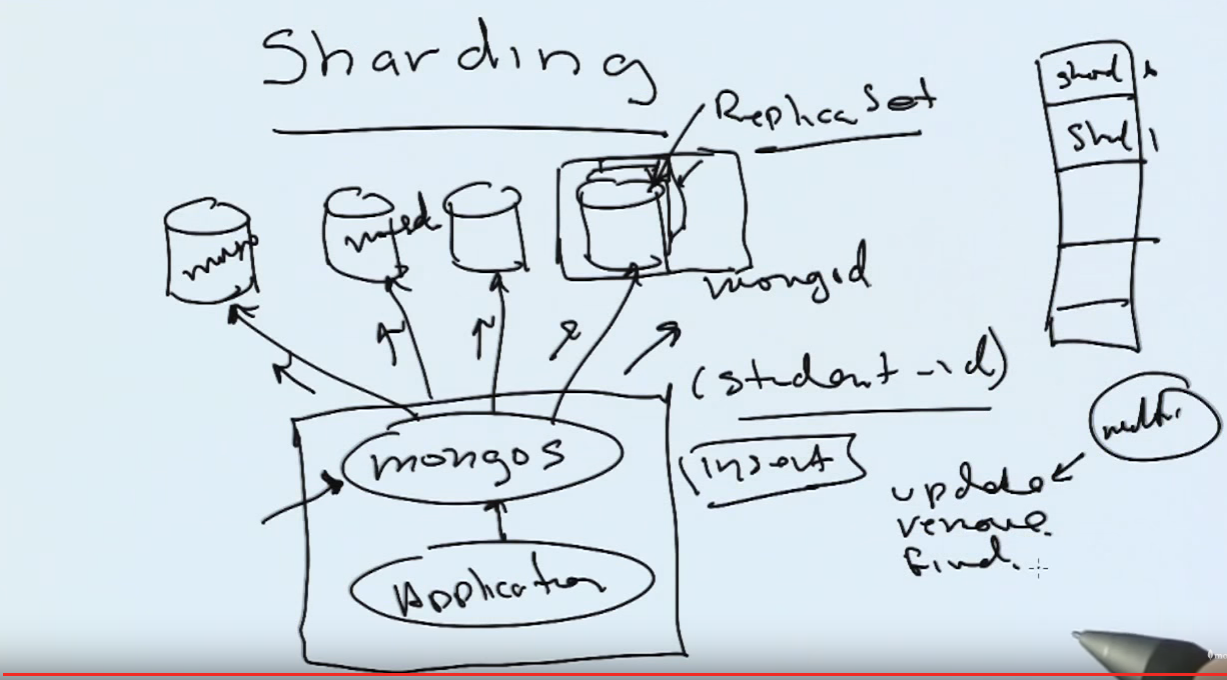
Splitting a large collection amongst multiple servers. The details can be transparent to the client. mongos routes to multiple mongod shards. Each shard can contain multiple servers as a replica set.
An insert must contain the shard key, e.g. student_id. For update, remove, and find, if a shard key is not given, mongos will have to broadcast the requests to all the shards.
Resources
Link to the MongoDB tutorial series.
comments powered by Disqus