Mongodb Tutorial 6 - Application Engineering
Table of Contents
Durability of Writes
Write Concern
How to make sure the writes persistent? Assume application talking to a database server in the scheme below.
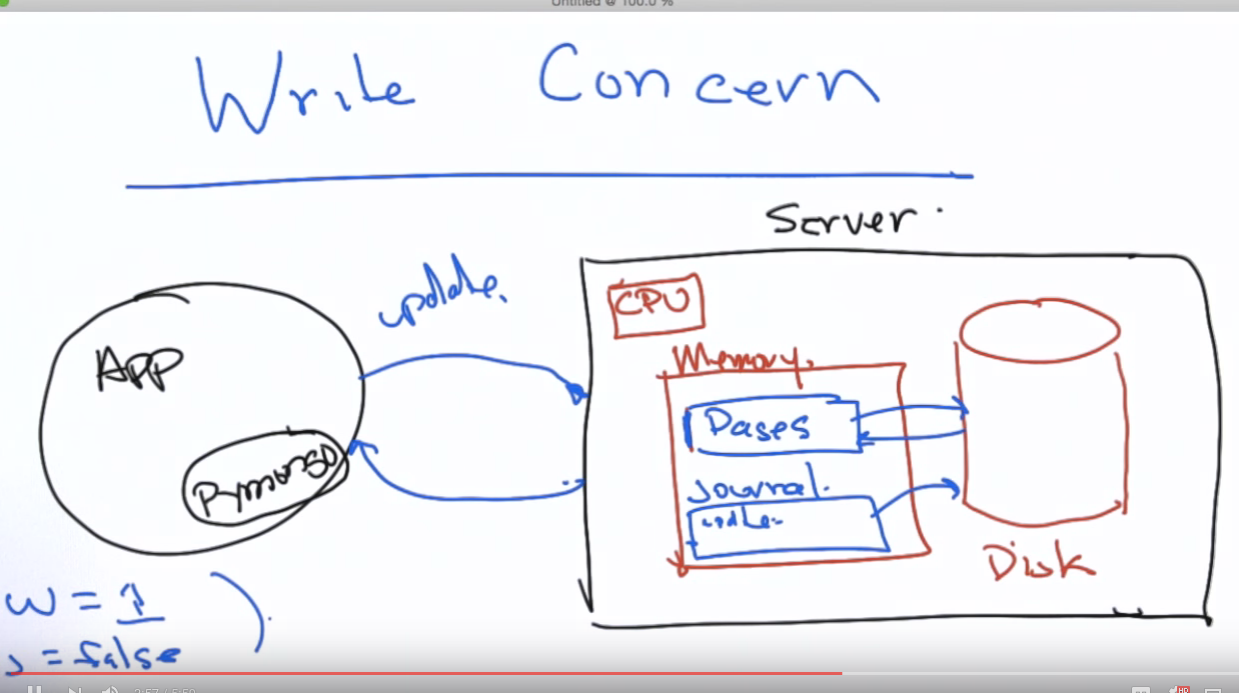
The settings of two parameters affect the write concern:
| w(wait for acknowledgement) | j(journal) | effect | comment |
|---|---|---|---|
| 1 | false | fast, small window of vulnerability | default setting |
| 1 | true | slow, no vulnerability | can be done inside driver at collection, database, or client level |
| 0 | - | unacknowledged write | do not recommend |
| 2 | - | wait for 2 nodes in replica set to acknowledge write | w can be 0-3 for a set with 3 nodes |
| majority | - | wait for majority to acknowledge, avoid rollback on failover | - |
| tag values | - | set tags on nodes | - |
If the journal has been written to disk and the server crashes, on recovery the server can look in the journal and recreate all the writes that were not yet persisted to the pages.
Write concern revisited video notes: Write concern (w) value can be set at client, database or collection level within PyMongo. When you call MongoClient, you get a connection to the driver, but behind the scenes, PyMongo connects to multiple nodes of the replica set. The w value can be set at the client level. Andrew says that the w concern can be set at the connection level; he really means client level. It’s also important to note that wtimeout is the amount of time that the database will wait for replication before returning an error on the driver, but that even if the database returns an error due to wtimeout, the write will not be unwound at the primary and may complete at the secondaries. Hence, writes that return errors to the client due to wtimeout may in fact succeed, but writes that return success, do in fact succeed. Finally, the video shows the use of an insert command in PyMongo. That call is deprecated and it should have been insert_one.
w, j, and wtimeout collectively are called write concern, they can be set:
- at the time of connection, client level
- at the collection level through the driver
- in the configuration of the replica set, safest from sys admin standpoint
j, waiting for journal committed at the primary node only, not waiting for secondary nodes.
If you set w=1 and j=1, is it possible to wind up rolling back a committed write to the primary on failover? Yes. If the primary goes down before the write propagates to secondaries, it will roll back when it recovers.
Network Errors
Network errors can cause a failed affirmative response sent back but the write may have succeeded, e.g. a TCP reset. For an insert, it is possible to guard against this since multiple times inserts will cause no harm. Worst case scenario is you get a duplicate key error. The problem is for updates, e.g. a $inc operation, if you do not know the values, there is no possible way to check whether it succeeded with a network error.
Generally, when the network is healthy, this type of error is rare. If you want to avoid it at all cost, you can turn all updates into inserts and deletes.
Replication (MongoDB’s Approach to Fault Tolerance and Availability)
Replication helps to solve both availability and fault tolerance. A replica set is a set of mongo nodes (mongod) that act together and all mirror each other in terms of data. There is one primary node and the rest are dynamic secondary nodes. Data written to the primary will asynchronously replicate to the secondaries. Application connects to the primary only. If the primary goes down, there will be an election for a new primary all transparent to the application.
The minimum number of nodes is three.
Replica Set Elections
Types of replica set nodes:
- regular (primary/secondary)
- arbiter, just for election/voting purposes, no data
- delayed, often disaster recovering node(1h behind). Set priority=0 (p=0) and it cannot become a primary node.
- hidden, never primary, p=0, often used for analytics, can vote.
Typically each node has one vote.
Write Consistency
MongoDB has strong consistency, vs. some others have eventual consistency. In the default configuration, application reads from and writes to the primary node. You will not read stale data in strong consistency. The writes have to go to the primary. The reads can go to the secondaries for eventual consistency. The lag is not guaranteed since the replication is asynchronous. One reason to do it is to scale the reads to the replica set. When failover occurs (usually under 3 seconds), write cannot complete.
Eventual consistency might be harder to reason about. Most application servers are stateless, write and read back out and get a different value, then have to reconcile.
Create a Replica Set
# bash < create_replica_set.sh
#!/usr/bin/env bash
# 3 on a single node so different ports
# --fork so do not have to run each in its own shell
mkdir -p /data/rs1 /data/rs2 /data/rs3
mongod --replSet m101 --logpath "1.log" --dbpath /data/rs1 --port 27017 --oplogSize 64 --fork --smallfiles
mongod --replSet m101 --logpath "2.log" --dbpath /data/rs2 --port 27018 --oplogSize 64 --smallfiles --fork
mongod --replSet m101 --logpath "3.log" --dbpath /data/rs3 --port 27019 --oplogSize 64 --smallfiles --fork
$ mongo --port 27018 < init_replica.js
config = { _id: "m101", members:[
{ _id : 0, host : "localhost:27017", priority:0, slaveDelay:5},
// delayed 5 seconds, not primary
{ _id : 1, host : "localhost:27018"},
{ _id : 2, host : "localhost:27019"} ]
};
rs.initiate(config);
rs.status();
rs.conf(); // show the configuration
rs.help(); // replica set commands help
$ mongo --port 27018
MongoDB shell version 2.2.0
connecting to: 127.0.0.1:27018/test
m101:SECONDARY> rs.status()
# will see 3 members two in RECOVERING stateStr, one in PRIMARY.
# Momentarily, one in PRIMARY, two in SECONDARY. Prompt also changes to primary.
m101:PRIMARY> db.people.insert({'name':'Andrew'})
$ mongo --port 27019
m101:SECONDARY> rs.slaveOk() # allow to read from secondary
m101:SECONDARY> db.people.find()
Normally when you create replicate sets, you would want the mongods on different physical servers so there is real fault tolerance.
Replica Set Internals
oplog (operation log?) kept in sync by mongo. The secondaries are constantly reading the oplog of the primary. It’s true that the oplog entries originally come from the primary, but secondaries can sync from another secondary, as long as at least there is a chain of oplog syncs that lead back to the primary.
Use $ ps -ef | grep mongod to check the mongod processes that are running.
m101:PRIMARY> use local
m101:PRIMARY> show collections
oplog.rs
startup_log
m101:PRIMARY> db.oplog.rs.find().pretty()
"op" : "i" # insert
"ns" : "test.people" # into test.people
"o" : {_id: ..., name: "Andrew" }
"op" : "c" # create collection
"ns" : "test.$cmd"
"o" : { create:people }
m101:SECONDARY> db.oplog.rs.find().pretty()
# should see exactly the same log as in primary
optime and optimeDate # whether this node is up to date
syncingTo # where it gets its data from
- oplog is a capped collection, which rolls off at certain times. The oplog needs to be big enough to deal with periods where the secondary can’t see the primary. The oplog’s size depends on how long you expect there to be a bifurcation of the network and how much data you are writing, how fast the oplog is growing. If the oplog rolls over and the secondary can’t get to the primary’s oplog, you can still resync the secondary but he has to read the entire database (much slower).
- oplog uses a statement (MongoDB documents) based approach, which allows mixed mode replica sets (flexibility on storage engines or even mongodb versions). And this helps doing (rolling) upgrades in the system.
Replica set election:
$ kill 60494 # found by ps primary
# the other shell window already changed prompt within 1s already primary
stateStr : (not reachable/health) # the one killed
Connect with Java Driver
# after inserting some documents into the primary
replset:PRIMARY> rs.stepdown() # simulate a failover
replset:SECONDARY>
The older way to initiate a MongoClient will fail on a failover since it will wait until it connects to a primary before insertion. Instead, pass in Arrays.asList(new ServerAddress("localhost", 27017)) will work because the driver can discover the primary through the secondary. This will not work if the process of 27017 was killed.
The list of mongod servers here is refereed to as a seedlist.
Bump up log level:
<root level="WARN">
<appender-ref ref="STDOUT"/>
</root>
<!-- change first line -->
<root level="INFO">
What to do in the catch clause when we catch a MongoSocketException? It depends on the application.
- try insertion again if it is idempotent (contains a specific _id and that the field has a unique index).
- put this message into another system.
- notify a system admin.
- return error to the user.
A robust solution (in python) is to put inserts into a retry loop for 3 tries. If the insertion is successful, it will break out the retry loop. If a AutoReconnect error occurs, time.sleep(5) sleep for full 5 seconds and go back to the second try in the retry loop. We need to handle the DuplicateKeyError since the insert may have succeeded even we got the AutoReconnect error.
$inc, $push operators are not idempotent and may cause issues in scenarios of AutoReconnect error but the actual insert/update have succeeded. You can’t just retry. $set is idempotent. We can turn $inc into a find() plus a $set and the operation is now idempotent but is no longer atomic (you can lose a vote if two threads try to update at the same time).
Failover and Rollback
Even if you set w=1 j=1 on the primary, if the node fails before the write gets synced to the secondaries, when it comes back up it will roll back the writes. One way to avoid it mostly is to set w=majority (wait until the majority of the nodes have the data then the vulnerability does not exist for the most part, small corner cases below).
While it is true that a replica set will never rollback a write if it was performed with w=majority and that write successfully replicated to a majority of nodes, it is possible that a write performed with w=majority gets rolled back. Here is the scenario: you do write with w=majority and a failover occurs after the write has committed to the primary but before replication completes. You will likely see an exception at the client. An election occurs and a new primary is elected. When the original primary comes back up, it will rollback the committed write. However, from your application’s standpoint, that write never completed, so that’s ok.
Read Preference
The driver connects to the primary node and maintains connections to the secondary nodes as well. By default, reads and writes go to the primary. Read preference settings:
- primary
- primary preferred
- secondary, eventually consistency
- secondary preferred
- nearest (in terms of pin time, < 15ms considered nearest, can have a tag set, data center awareness idea)
If read preference is set to secondary only, for the case of primary stepdown, the python code does not have to handle exception.
One thing to remember is that the driver will check, upon attempting to write, whether or not its write concern is valid. It will error if, for example, w=4 but there are 3 data-bearing replica set members. This will happen quickly in both the Java and pymongo drivers. Reading with an invalid read preference will take longer, but will also result in an error. Be aware, though, that this behavior can vary a little between drivers and between versions.
Sharding (Distributed MongoDB)
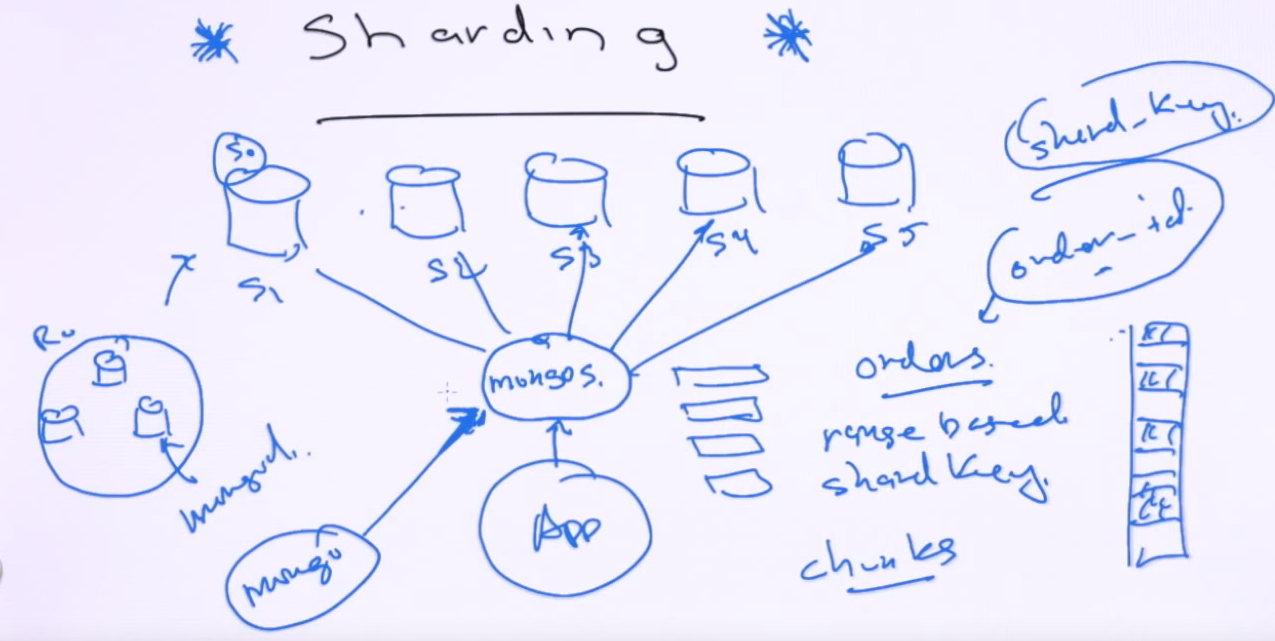
Sharding introduces horizontal scalability. Shards split data up from a particular collection. Shards are typically replica sets themselves. Application sends commands through mongos routers to the shards. For example, an orders collection can be sharded range based with a shard key of order_id. The router will keep maps of key ranges to chunks and mapping of chunks to the shards. If the query does not include a shard key, the query will be scattered to all the shard servers and gather back the answer and respond to the application. Shard key have to be included in inserts.
Sharding is at a database/collection level. Collections not sharded will sit in the first shard (shard 0). The routers are pretty stateless and are handled similarly to a replica set.
As of MongoDB 2.4, we also offer hash-based sharding, which offers a more even distribution of data as a function of shard key, at the expense of worse performance for range-based queries.
Building a Sharded Environment
Probably more of a DBA task. The example will build 3 shards: s0, s1, and s2, each is a replica set with 3 nodes (mongod --shardsvr); 1 mongos at port 27017 (mognos --configdb); 3 config servers (mongod --configsvr) holding information about the way of how data are distributed across the shards (map chunks to shards). There are two ways to shard:
- ranged based O(lgN) assuming binary search based
- hash based O(1), O(lgN) worst case, under universal hashing assumption
Every document must have a shard key that is indexed, but does not have to be unique.
$ mongo # mongos at 27017
mongos> sh.status()
# see info about shards: {...}, chunks, .etc
mongos> db.students.explain().find({}).limit(10)
# stage: "SHARD_MERGE", goes to all three shards
mongos> db.students.explain().find({student_id:1000}).limit(10)
# only goes to s0 shard, IXSCAN
Implications of Sharding on Development
- every document needs to include a shard key
- the shard key is immutable
- index that starts with the shard key, cannot be a multikey index
- when doing an update, specify shard key or multi is true
- no shard key means scatter gather operation
- no unique index unless starting with the shard key. There is no way of enforcing the uniqueness of an index if it doesn’t include the shard key because it doesn’t know whether or not copies exist on different shards. The indexes are on each shard.
Sharding and replication are almost always done together. Usually mongos is replicated itself typically run on the same box as the application since they are pretty lightweight.
Choosing a Shard Key
- Sufficient cardinality, e.g., 3 possible values across 100 shards not good. You can put in a second part of the key with more cardinality.
- Avoid hotspotting in writes, which occurs for anything monotonically increasing (BSON ID, high part is time stamp). First chunk starts with
$minkeyand last chunk ends with$maxkey. It will always get assigned to the highest chunk.
For example, we are sharding on billions of orders and the order_ids are monotonically increasing. So maybe shard on (vendor, order_date) considering the two aspects above. Think about how was the problem naturally parallel? Cannot redo since they are immutable. Needs careful design, testing before commit to one.
Resources
Link to the MongoDB tutorial series.
comments powered by Disqus