MongoDB Tutorial 5 - Aggregation Framework
Category: tutorial Tags: [mongodb] [NoSQL] [database] [python] [java]
Table of Contents
The aggregation framework has its roots in SQL’s world of groupby clause.
Introduction
Example used: imagine a SQL table of products.
| name | category | manufacture | price |
|---|---|---|---|
| ipad | tablet | Apple | 499 |
| nexus s | cellphone | Samsung | 350 |
To get number of products from each manufacture with SQL,
select manufacture, count(*) from products
group by manufacture;
with mongodb,
> use agg
> db.products.aggregate([ // array
{$group:
{
_id:"$manufacturer", // creating new collection
num_products:{$sum:1}
} // a series of upserts
}
])
{"_id" : "Amazon", "num_products" : 2}
{"_id" : "Sony", "num_products" : 1}
To do compound grouping with SQL,
select manufacturer, category, count(*) from
products group by manufacturer, category
with mongodb,
> db.products.aggregate([
{$group:
{
// _id can be a complex document, just have to be unique
_id:{"manufacturer":"$manufacturer","category":"category"},
num_products:{$sum:1}
}
}
])
{"_id" : {"manufacturer":"Amazon", "category":"Tablets"}, "num_products" : 2}
SQL to Aggregation Mapping Chart .
One can group on _id:null to aggregate every single document such as counting or summing.
Aggregation Pipeline
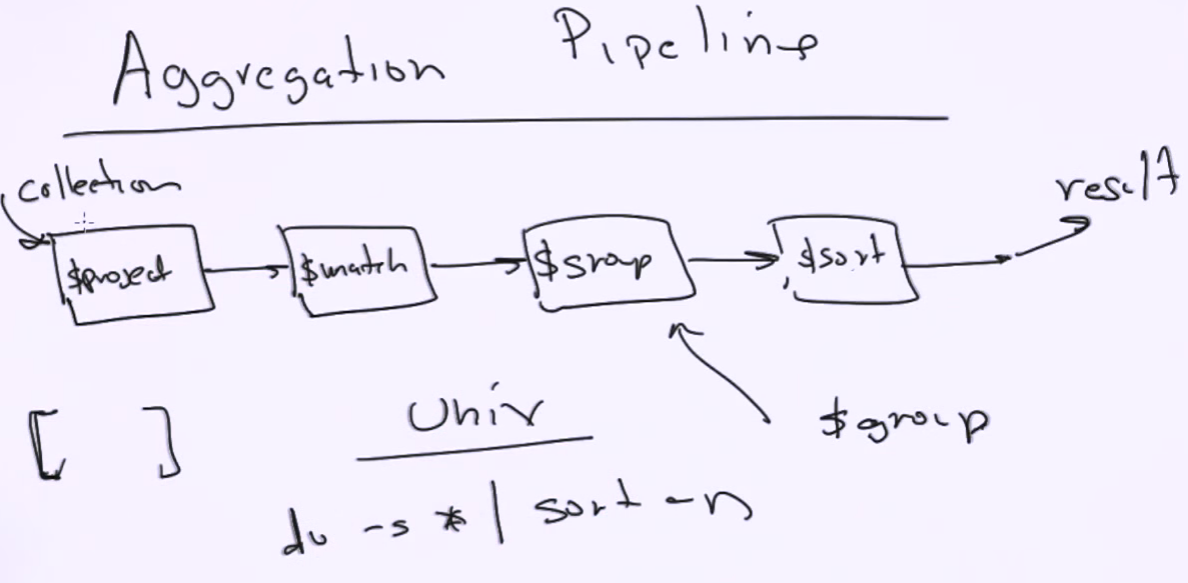
| pipeline stages | job | documents handling |
|---|---|---|
$project |
reshape documents, select out fields potentially deep in hierarchy | 1:1 |
$match |
filter out | n:1 |
$group |
aggregate | n:1 |
$sort |
sorting | 1:1 |
$skip |
skips | n:1 |
$limit |
limit | n:1 |
$unwind |
normalize, flatten data before grouping | 1:n |
$out |
redirect output | 1:1 |
$redact |
security related | - |
$geonear |
location based searching | n:1 |
$unwind example: tags:[red, blue] unwinds to tag:red and tag:blue, expanding the number of documents.
More Operators with Examples
The $sum operator:
> db.products.aggregate([ // array
{$group:
{
_id:{"maker":"$manufacturer"}, // creating new collection
sum_prices:{$sum:"$price"}
} // a series of upserts
}
])
{"_id" : {"maker":"Amazon"}, "sum_prices" : 328}
The $avg operator:
> db.products.aggregate([ // array
{$group:
{
_id:{"category":"$category"}, // creating new collection
avg_prices:{$avg:"$price"}
} // a series of upserts
}
])
{"_id" : {"category":"Tablets"}, "avg_prices" : 396.42714}
The $addToSet operator without counterpart in SQL:
> db.products.aggregate([ // array
{$group:
{
_id:{"maker":"$manufacturer"}, // creating new collection
categories:{$addToSet:"$category"}
} // a series of upserts
}
])
{"_id" : {"maker":"Apple"}, "categories" : ["Laptops", "Tablets"]}
The $push operator:
> db.products.aggregate([ // array
{$group:
{
_id:{"maker":"$manufacturer"}, // creating new collection
categories:{$push:"$category"}
} // a series of upserts
}
])
{"_id" : {"maker":"Apple"}, "categories" :
["Tablets", "Tablets", "Tablets", "Laptops"]}
The $max and $min operators:
> db.products.aggregate([ // array
{$group:
{
_id:{"maker":"$manufacturer"}, // creating new collection
maxprice:{$max:"$price"}
} // a series of upserts
}
])
{"_id" : {"maker":"Apple"}, "maxprice" : 699 }
The $project phase/stage: you can remove, add, reshape keys, use simple functions on keys such as $toUpper, $toLower, $add, $multiply.
db.products.aggregate([
{$project:
{
_id:0,
'maker': {$toLower:"$manufacturer"},
'details': {'category': "$category",
'price' : {"$multiply":["$price",10]}
},
'item':'$name'
}
}
])
{"maker":"amazon", "details":{"category":"Tablets", "price":1990},
"item":"Kindle Fire"}
The $match phase. One thing to note about $match (and $sort) is that
they can use indexes
, but only if done at the beginning of the aggregation pipeline.
Example zips collection.
db.zips.aggregate([
{$match:
{
state:"NY"
}
},
{$group:
{
_id: "$city",
population: {$sum:"$pop"},
zip_codes: {$addToSet: "$_id"}
}
},
{$project:
{
_id: 0,
city: "$_id",
population: 1,
zip_codes:1
}
},
{$sort:
{population:-1}
},
{$skip:10},
{$limit:5}
])
{"population":9743, "zip_codes":[96162, 96161], "city":"TRUCKEE"}
// order of fields not retained
$sort operator. The aggregation framework supports both memory (default, 100 MB limit for each pipeline stage unless allowing disk) and disk based sorting. Sorting can be done before or after the grouping stage.
$skip and $limit works similarly in find().
$unwind operator: it’s not easy to group on the array elements (prejoined data) so we need to flatten (unjoin, data explosion) the array.
To count how many posts were attached to each tag in the blog,
use blog;
db.posts.aggregate([
/* unwind by tags */
{"$unwind":"$tags"},
/* now group by tags, counting each tag */
{"$group":
{"_id":"$tags",
"count":{$sum:1}
}
},
/* sort by popularity */
{"$sort":{"count":-1}},
/* show me the top 10 */
{"$limit": 10},
/* change the name of _id to be tag */
{"$project":
{_id:0,
'tag':'$_id',
'count' : 1
}
}
])
To reverse $unwind
You can use $push to reverse the effects of an $unwind. If the array elements were unique, $addToSet will also do the job.
More Advanced Aggregation Examples
Double Grouping
For a collection of student grades like below:
{ "_id" : { "$oid" : "50b59cd75bed76f46522c34e" },
"student_id" : 0, "class_id" : 2,
"scores" : [ { "type" : "exam", "score" : 57.92947112575566 },
{ "type" : "quiz", "score" : 21.24542588206755 },
{ "type" : "homework", "score" : 68.19567810587429 },
{ "type" : "homework", "score" : 67.95019716560351 },
{ "type" : "homework", "score" : 18.81037253352722 }]
}
We want to figure out the average class grade for each class,
db.grades.aggregate([
{'$group':{_id:{class_id:"$class_id", student_id:"$student_id"},
'average':{"$avg":"$score"}}
}, // pipe to a secondary grouping stage
{'$group':{_id:"$_id.class_id", 'average':{"$avg":"$average"}}}
])
$first and $last, example: find city with largest population in each state.
b.zips.aggregate([
/* get the population of every city in every state */
{$group:
{
_id: {state:"$state", city:"$city"},
population: {$sum:"$pop"},
}
},
/* sort by state, population */
{$sort:
{"_id.state":1, "population":-1}
},
/* group by state, get the first item in each group */
{$group:
{
_id:"$_id.state",
city: {$first: "$_id.city"},
population: {$first:"$population"}
}
},
/* now sort by state again */
{$sort:
{"_id":1}
}
])
$out redirects the output to a new collection, write over, no appending, considering a games collection with documents structured like,
{
"_id":ObjectId("53684890"),
first_name: "Jerzy",
last_name: "Fischer",
points: 3,
moves: [1,2,5]
}
To summarize each person’s points,
db.games.aggregate([
{$group:
{_id:{first_name:"$first_name", last_name:"$last_name"},
points:{$sum:"$points"}
}
},
{$out:"summary_results"}
])
Note that the _id field of the redirected output must be unique, the operations below will not succeed and leave the summary_results collection untouched.
db.games.aggregate([
{$unwind:"moves"},
{$out:"summary_results"}
])
Double $unwind
Create a Cartesian product of the two or more arrays.
db.inventory.aggregate([
{$unwind: "$sizes"},
{$unwind: "$colors"},
{$group:
{
'_id': {'size':'$sizes', 'color':'$colors'},
'count' : {'$sum':1}
}
}
])
To reverse with $addToSet in one stage since array elements were unique,
db.inventory.aggregate([
{$unwind: "$sizes"},
{$unwind: "$colors"},
{$group:
{
'_id': "$name",
'sizes': {$addToSet: "$sizes"},
'colors': {$addToSet: "$colors"},
}
}
])
To reverse with $push,
db.inventory.aggregate([
{$unwind: "$sizes"},
{$unwind: "$colors"},
/* create the color array */
{$group:
{
'_id': {name:"$name",size:"$sizes"},
'colors': {$push: "$colors"},
}
},
/* create the size array */
{$group:
{
'_id': {'name':"$_id.name",
'colors' : "$colors"},
'sizes': {$push: "$_id.size"}
}
},
/* reshape for beauty */
{$project:
{
_id:0,
"name":"$_id.name",
"sizes":1,
"colors": "$_id.colors"
}
}
])
Full Text Search and Aggregation
“Two great taste that go great together.” - Andrew Erlichson.
db.sentences.aggregate([
{$match:{$text:{$search:"tree rat"}}},// must appear first
// one full text search per collection, no need to specify
{$sort:{score:{$meta:"textScore"}}},
{$project:{words:1, _id:0}}
])
{"words":"rat shrub granite."}
$text is only allowed in the $match stage of the aggregation pipeline and must be the first stage of the aggregation pipeline.
Aggregation with Java driver
public class ZipCodeAggregationTest {
public static void main (Strng[] args) {
MongoClient client = new MongoClient();
MongoDatabase database = client.getDatabase("course");
MongoCollection<Document> collection = database.getCollection("zipcodes");
// verbose
// List<Document> pipeline = Arrays.asList(new Document("$group",
// new Document("_id", "$state").append("totalPop", new Document(
// "$sum", "$pop"))), new Document("$match", new Document("totalPop",
// new Document("$gte", 10000000))));
List<Bson> pipeline = Arrays.asList(Aggregates.group("$state", Accumulators.sum("totalPop",
"$pop")), Aggregates.match(gte("totalPop", 10000000)));
List<Document> pipeline2 = Arrays.asList(Document.parse(
"{ $group: { _id: \"$state\", totalPop: { $sum: \"$pop\" } } }"),
Document.parse("{ $match: { totalPop: { $gte: 1010001000 } } }"));
List<Document> results = collection.aggregate(pipeline).
into(new ArrayList<Document>());
// List<Document> results = collection.find().into(new ArrayList<Document>());
for (Document cur : results) {
System.out.println(cur.toJson());
}
}
}
Aggregation Options
explaingets the query plan if we ran it, useful in optimization.allowDiskUseallows use of hard drive for intermediate stages. Any stage is limited to 100 MB of memory use and will fail if exceeded. Certain stages like projection run the documents through and don’t use a lot of memory.cursorallows cursor use and specify cursor size.
use agg
db.zips.aggregate(
[{$group:{_id:"$state", population:{$sum:"$pop"}}}],
{explain:true},
{allowDiskUse:true}
)
Two forms of aggregation:
aggregate([stage1, stage2, ...])aggregate(stage1, stage2, ...)cannot add options
Prior to the release of the 3.0 pymongo driver, you would get a document for aggregation queries by default (the aggregation result is limited by the 16 Mb size), though you had the option of getting back a cursor if you were working with MongoDB 2.6.0+, and your pymongo version was 2.6.0+. Starting with the release of the 3.0 pymongo driver, however the aggregation pipeline queries using the driver will now return a cursor by default.
The mongo shell returns a cursor by default starting 2.6.0.
import pymongo
connection = pymongo.MongoClient()
db = connection.agg
result = db.zips.aggregate([{'$group':{'_id':'state',
'population':{'$sum':'$pop'}}}])
print result
# <pymongo.command_cursor.CommandCursor object at 0x7f62829f5210> in 3.2.6
# piror to 3.0
result = db.zips.aggregate([{'$group':{'_id':'state',
'population':{'$sum':'$pop'}}}], cursor={}, allowDiskUse=True)
for doc in result:
print doc
# prior to 3.0
{u'ok':1.0, u'result' : [array of resulted documents]}
Limitations of Aggregation framework
- 100 MB limit for pipeline stages,
allowDiskUseto get around. - 16 MB limit if you decide to return the result as a single document, set
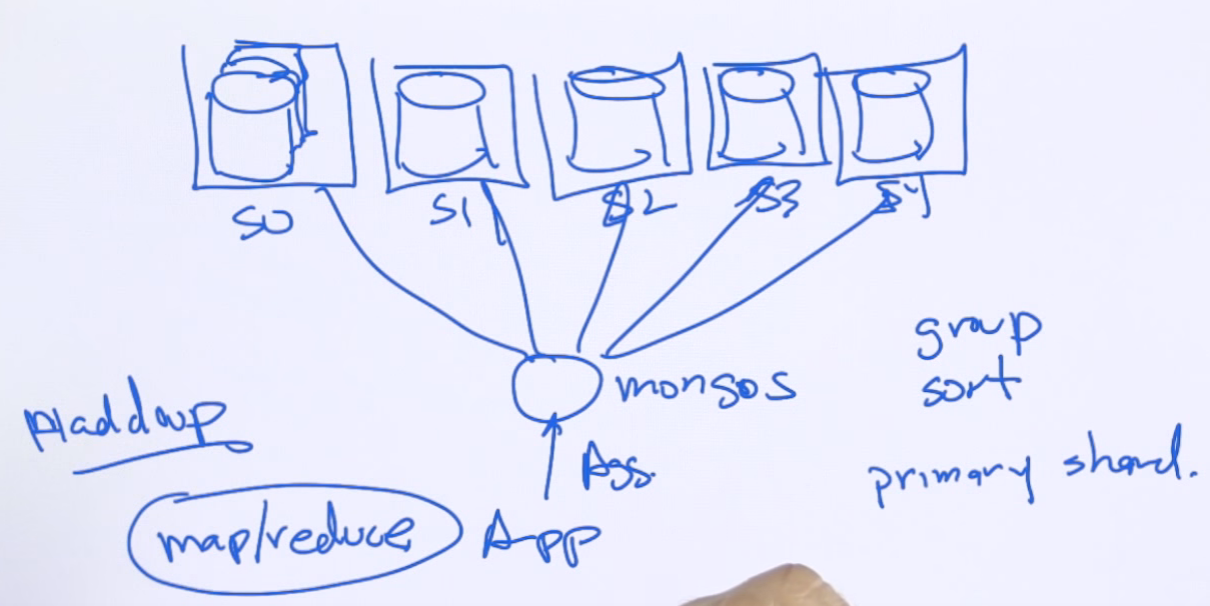
cursor. - In a sharded system, stages like
$group,$sortwill bring back the results to the first shard. Stages like$matchand$projectcan go in parallel. Aggregation in mongodb is an interface to map/reduce jobs. Alternatively, get the data out of mongodb using the hadoop connector and use Hadoop map/reduce. There is a map/reduce functionality built into mongodb that is not recommended.
Resources
Link to the MongoDB tutorial series.
comments powered by Disqus